Benchmarks for biology agents are messy for a simple reason: biology work is messy. Questions can be underspecified, grading can depend on method choices, and sometimes the benchmark answer key is just wrong.
That's why Phylo's recent writeup on biology-agent evaluation caught our attention. Their main point is hard to argue with: if you want to know how good an agent actually is, you first have to clean up the benchmark. BixBench-Verified-50 is their attempt to do exactly that.
We ran K-Dense Web on that verified subset and scored 45/50, or 90.0% accuracy.
Why the verified subset matters
The original BixBench benchmark is useful, but it mixes together a few different kinds of failures:
- real agent mistakes
- ambiguous or underspecified questions
- incorrect or inconsistent ground truth
That distinction matters. If an agent picks a defensible method and gets marked wrong because the benchmark expected a different unstated choice, that does not tell you much about the agent. It tells you the eval needs work.
BixBench-Verified-50 is more interesting because it tries to remove that noise. According to Phylo's description, the subset was reviewed with domain experts, with problematic questions removed, wording clarified, and incorrect answers fixed. That makes the score more meaningful than a raw pass/fail number on the original benchmark.
Our result
K-Dense Web scored 45 out of 50 on the verified set.
| Metric | Result |
|---|---|
| Total questions | 50 |
| Correct | 45 |
| Accuracy | 90.0% |
| Total runtime | ~103 minutes |
| Average runtime per question | 123.6 seconds |
Here is the benchmark comparison plot for this run:
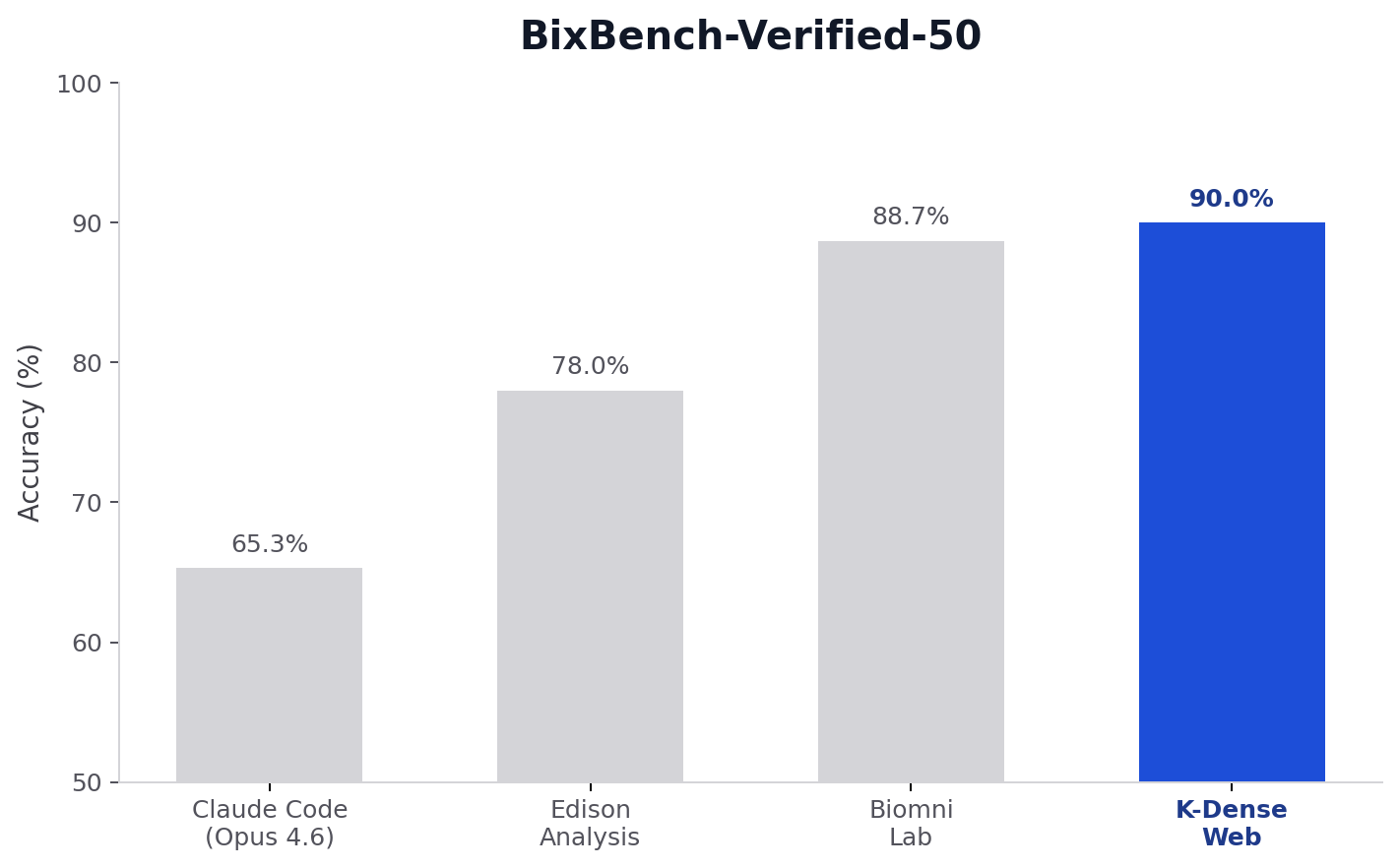
For additional context, Phylo reported the following BixBench-Verified-50 scores for other systems in their public post. We are placing our run alongside them here:
| System | Accuracy |
|---|---|
| K-Dense Web | 90.0% |
| Biomni Lab | 88.7% |
| Edison Analysis | 78.0% |
| Claude Code (Opus 4.6) | 65.3% |
| OpenAI Agents SDK (GPT-5.2) | 61.3% |
Those numbers should always be read with some caution because prompting, tools, and run conditions matter. Still, the headline is straightforward: K-Dense Web performed very strongly on a version of BixBench that was explicitly designed to be less noisy and more fair.
That result is especially notable because K-Dense Web is a generalist intelligent system. It is not a bioinformatics-only product or a benchmark-specialized agent tuned just for BixBench. The same platform is built to handle research, coding, data analysis, machine learning, and multi-step technical workflows across domains. Even without being optimized specifically for bioinformatics, it performed at the top of a demanding biology benchmark.
Breakdown by verifier type
The verified subset uses three grading modes: LLM-based judging, exact-string matching, and numeric range checks. K-Dense Web performed well across all three.
| Verifier type | Correct | Total | Accuracy |
|---|---|---|---|
| LLM verifier | 18 | 20 | 90.0% |
| String verifier | 15 | 17 | 88.2% |
| Range verifier | 12 | 13 | 92.3% |
That spread is useful. The score is not being carried by one easy slice of the benchmark. We saw strong performance on judged answers, exact-answer tasks, and quantitative outputs.
What the remaining misses tell us
A 90.0% score is strong, but it is not perfect. We still missed five questions:
- 2 on LLM-judged answers
- 2 on exact-string answers
- 1 on a numeric range check
Here are the five misses from the run:
| Question ID | Verifier | Expected | K-Dense Web answer | What happened |
|---|---|---|---|---|
bix-43-q2 |
String | 5.81 |
5.831005059276599 |
Numerically close, but failed exact string matching |
bix-61-q5 |
LLM judge | 2.68 |
2.56 |
Small quantitative miss on a judged answer |
bix-27-q5 |
Range | (55,56) |
56.471704739574804 |
Slightly outside the accepted range |
bix-16-q1 |
String | CDKN1A |
CCND1 |
Wrong exact answer |
bix-45-q1 |
LLM judge | 7.6968e-54 |
1.8037401775486344e-47 |
Large numeric mismatch on a judged answer |
This table is useful because the misses are not all the same. Two are basically formatting or precision problems, one is a narrow range miss, and two are substantive answer misses. That is a better place to be than having one systematic failure mode tank the entire benchmark, but it also makes clear where the next round of improvements should go.
Why this result matters
The bigger story is not just that K-Dense Web scored well. It is that verified benchmarks tell a clearer story about what these systems can already do.
If you look only at noisy benchmarks, you can come away thinking biology agents are much worse than they are in practice. If you clean up the questions and grading, a different picture emerges: good systems are already capable of completing a large share of real bioinformatics analysis tasks correctly.
That matches what we see with users. The value is not in producing a nice-looking answer and hoping for the best. It is in running the analysis, choosing reasonable methods, and getting to a result that holds up under inspection.
BixBench-Verified-50 is not the final word on evaluation, and Phylo is right to argue that biology needs more process-aware benchmarks over time. But as a checkpoint for current capability, this one is useful. On that checkpoint, K-Dense Web scored 90.0%.
At the same time, benchmarks only go so far. The hardest scientific work usually does not look like a fixed multiple-choice or short-answer eval. Real research involves messy datasets, unclear problem definitions, partial context, changing objectives, and output formats that depend on the downstream decision. No current benchmark really captures that full picture.
Try it yourself
If you want to run your own biology analyses, benchmark agent workflows, or pressure-test a scientific question end to end, K-Dense Web is built for exactly that kind of work. We would encourage anyone evaluating the platform to go beyond benchmark scores and test it on their own hardest research problems. That is the standard that matters most.