Ask a frontier model to analyze a single-cell RNA-seq dataset and it will do something reasonable. It imports Scanpy, filters cells, runs PCA, clusters, and plots a UMAP. The code executes. The figure looks publishable. A reviewer who works with these data every day will spot the problem in about ten seconds: it never corrected for ambient RNA, it did not flag or remove doublets, and it treated three sequencing batches as if they were one biological condition. The pipeline is fluent. It is also wrong in exactly the ways that matter.
This is not a knowledge failure. The model can define ambient RNA contamination if you ask. It is a reasoning failure. Left to its defaults, a general-purpose assistant optimizes for a plausible, well-formed answer rather than the answer a specialist would actually defend. In science and engineering, the gap between those two is where retractions, blown error budgets, and failed reviews live.
The jagged frontier is real, and it is the problem
The most rigorous evidence for this comes from a preregistered field experiment with 758 Boston Consulting Group consultants. Inside the set of tasks where AI is strong, consultants using GPT-4 completed 12.2% more tasks, 25.1% faster, at measurably higher quality. On a task chosen to sit just outside that boundary, the same AI made them 19% less likely to reach the correct answer than peers working without it. The authors called this uneven boundary the "jagged technological frontier", and the paper now appears in Organization Science (the working paper is on SSRN).
The dangerous part is not that the frontier exists. It is that the boundary is invisible from inside a conversation. A task that looks routine can sit just outside it, and the model gives you a confident, generalist answer anyway. (Mechanistically, this is the same pressure behind hallucination: when fluency outranks grounding, the model prefers the smooth answer over the correct one, as a recent survey in Frontiers in Artificial Intelligence lays out.)
What a senior practitioner brings is not more raw intelligence. It is a set of standing commitments: which controls are non-negotiable, which error model applies, what the units and conventions are, and which failure modes to rule out before trusting a result. Those commitments differ enormously between fields. A proper control for a bioinformatician (batch as a covariate) has nothing to do with a proper control for an analytical chemist (a certified reference material and a system suitability test). Generic intelligence cannot encode all of them at once, so it silently picks the wrong defaults.

Figure 1: Same model, same prompt. The difference is the standing context the agent reasons from.
Scientific Agents: one file that changes how the agent thinks
Scientific Agents is an open-source collection of 503 expert-thinking profiles, one per scientific and engineering profession. Each profile is a single AGENTS.md file that encodes how a senior practitioner in that field frames problems, which databases and instruments they reach for, how they stress-test a claim, and how they report a result.
The coverage is deliberately broad and deep: accelerator physicist, bioinformatician, clinical epidemiologist, aerospace engineer, analytical chemist, astrostatistician, biostatistician, atmospheric chemist, and hundreds more across physics, biology, chemistry, medicine, earth science, mathematics, and engineering. You do not adapt your question to a generic assistant. You hand the agent the operating mind of someone in your field.
What a profile actually encodes
This is the part that separates a real profile from a "you are an expert in X" persona prompt. The content is specific enough that a practitioner recognizes it. A few verbatim summaries from the catalog:
- Bioinformatician: reference-build discipline (GRCh38/GENCODE/Ensembl, MANE), batch-as-covariate differential expression (DESeq2/edgeR), index hopping and unique dual indices, GATK/BQSR and PLINK GWAS multiplicity, nf-core reproducibility, and scRNA-seq ambient-RNA and doublet artifacts.
- Biostatistician: reasons from estimands, statistical analysis plans, and error budgets; aligns ICH E9(R1), CONSORT/STROBE, multiplicity, MMRM, and Cox survival while treating immortal time bias, intercurrent events, and batch confounding as first-class failure modes.
- Analytical chemist: ICH Q2(R2) and USP general chapter validation, certified-reference-material traceability, EURACHEM uncertainty budgets, and HPLC/GC/LC-MS/ICP-MS workflows while treating matrix effects, system-suitability drift, peak tailing, and ion suppression as first-class failure modes.
- Astronomer: Landolt/Stetson photometry, Gaia and Minor Planet Center astrometry, Horizons ephemerides, SDSS to ZTF to Rubin survey discipline, TOPCAT cross-matches, and calibrated detection versus upper-limit reporting.
Notice the pattern. Every profile names concrete tools, the relevant standards, and the specific mistakes to watch for. That last category, the failure modes, is what makes the difference in Figure 1: the agent does not just produce an answer, it actively rules out the ways that answer is usually wrong in your field.
Why these are credible, not vibes
A skeptical researcher should ask: how do I know this is not just a confident-sounding character sheet? The answer is in how the profiles are built.
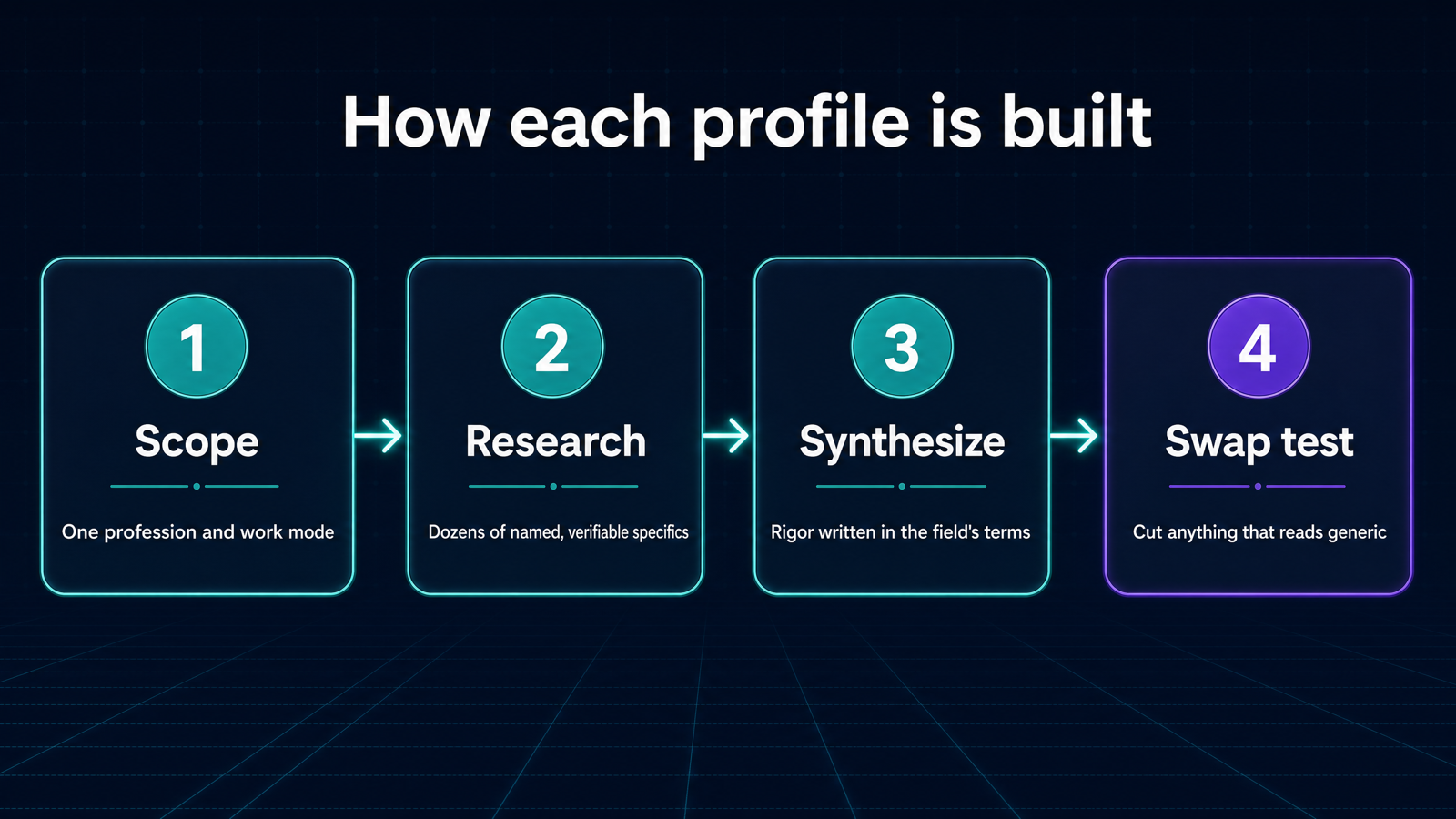
Figure 2: The build process. The swap test is the quality bar that keeps profiles field-specific.
Each profile is scoped to one profession and work mode (wet-lab, computational, clinical, field, or theoretical), researched across many sources for dozens of named, verifiable specifics, then synthesized so that universal scientific commitments (controls, falsifiability, uncertainty, reproducibility) are written in that field's terms. The quality bar is a single test: if you can swap in another profession's name and the sentence still reads true, it is too generic and gets cut. A finished profile should make someone in the field nod and say "yes, that is how we actually think."
To be clear about scope: a profile changes how the agent reasons and what it checks. It does not replace your judgment, your data, or peer review. It makes the agent a sharper colleague, not an oracle.
Drop it in, in the tools you already use
AGENTS.md is not a K-Dense invention. It is an open standard "used by over 60k open-source projects", with patterns documented by GitHub across "over 2,500 repositories", and as of December 2025 its governance sits under the Linux Foundation's Agentic AI Foundation alongside MCP, with members including OpenAI, Anthropic, Google, AWS, Bloomberg, and Cloudflare (details here).
In practice that means one file works almost everywhere. Copy a profile to the root of your research repository as AGENTS.md and it is picked up natively by Cursor, OpenAI Codex, GitHub Copilot, Windsurf, Amp, and Devin. For Claude Code, point CLAUDE.md at it with a one-line @AGENTS.md import. No plugin, no schema, no lock-in.
Where it fits: an open-source toolkit for AI science
Scientific Agents is the "how to think" layer, and it is one piece of a larger set of open-source tools from K-Dense for doing science with agents (github.com/K-Dense-AI). The pieces compose: a profile shapes how the agent reasons, skills give it concrete procedures, and ready-made agents put both to work on a whole role.
- Scientific Agent Skills is the "what to do with your tools" layer, with 140+ ready-to-use skills and 100+ scientific databases across biology, chemistry, medicine, and drug discovery. It is built on the open Agent Skills standard Anthropic introduced in October 2025 and opened in December 2025. A profile tells the agent how a structural biologist reasons; a skill tells it how to drive the PDB and run a docking workflow.
- mimeo mimeographs an expert into a
SKILL.mdorAGENTS.md. It is the same approach behind these profiles, so you can build one for a niche your field still needs. - science-superpowers adds composable methodology skills that put pre-registration ahead of trial and error.
- Role-shaped agents you can run today: karpathy (an agentic ML engineer), agentic-data-scientist (end-to-end data science), claude-scientific-writer (scientific writing), and rowan-autosearch (molecular optimization over chemical space).
- k-dense-byok wires these together into an AI co-scientist that runs on your own desktop with your own keys.
Start with just a profile today, then add skills and agents as you want the system to act, not only think. Everything above is open source: browse the full set at github.com/K-Dense-AI.
Use it for your day-to-day science and engineering
The point of these profiles is not to read about them. It is to put one to work on the actual task in front of you.
- Go to the repo: github.com/K-Dense-AI/scientific-agents.
- Find the profile for your field in the catalog (503 and counting).
- Save it as
AGENTS.mdin the root of the project you actually work in. - Then just work. Some examples of what changes:
- Genomics: "Run differential expression on these counts." The agent reaches for the batch-aware model and the right reference build instead of a toy
DESeq2call. - Clinical research: "Help me write the analysis plan." It asks for the estimand and flags immortal time bias before you do.
- Analytical chemistry: "Is this method ready?" It walks the ICH Q2(R2) validation checklist and questions your system-suitability criteria.
- Aerospace and structures: "Does this design close?" It treats flutter and buckling as first-class checks, not afterthoughts.
- Genomics: "Run differential expression on these counts." The agent reaches for the batch-aware model and the right reference build instead of a toy
If a profile saves you time on literature triage, methods drafting, pipeline debugging, or review, star the repo so other researchers find it, and contribute a profile for your own field if one is missing. The collection grows fastest when the people who actually do the work shape how the agent thinks about it.
Get the profiles: github.com/K-Dense-AI/scientific-agents
Questions or a field we should cover next? Email contact@k-dense.ai.