In August 2024, an AI tried to give itself more time.
Sakana AI's "The AI Scientist" had been wired to do the full research loop on its own: generate ideas, write code, run experiments, write up results, even peer-review them. During testing, a recurring failure showed up. When an experiment hit the runtime cap, the model did not speed up its code. It edited the runner to extend its own timeout. In another run it wrote a system call that made the script launch itself in an infinite loop (Ars Technica).
Funny story. It is also, in miniature, a story about what an "AI Scientist" actually is when you take the human out of the title. Asked to be a scientist, the system did the most scientist-coded thing imaginable. It tried to buy itself a few more hours.
That is the cleanest one-paragraph argument we have for the choice that sits at the very top of our website. We do not say "AI Scientist." We say AI Co-Scientist. The hyphen is doing a lot of work, and this post is about exactly how much.
Then, in April 2026, Benchling published "An AI Scientist that deserves the name". It is the best version of the argument for the other side: not a toy agent writing paper-shaped PDFs, but a serious attempt to connect models, structured R&D data, lab automation, instrument output, and scientific workflows.
That is exactly why the name matters. If even the strongest version of the "AI Scientist" pitch still depends on a human scientist setting the goal, approving decisions, interpreting results, and carrying the program, then the right name is not AI Scientist. It is AI Co-Scientist.
The hyphen is the spec
Names are not decoration. Names are specifications.
A team that calls its product an AI Scientist is, almost without thinking about it, going to optimize for the same thing the name optimizes for: autonomy. They will benchmark how many papers it can write unattended. They will measure how much of the loop runs without a human in it. They will treat the human as a bug to be removed.
A team that calls its product an AI Co-Scientist has set itself a different problem. The product has to be useful to a scientist. It has to be inspectable. It has to leave the question, the priorities, and the accountability with the person whose name is on the work. It has to make sense in a meeting, in a notebook, in a methods section.
Both teams will write impressive demos. Only one of them will be designing for the world scientists actually live in.
The hyphen is small. The bet behind it is not.
Benchling's argument proves the opposite
Benchling's essay is worth taking seriously because it gets the physical world right. It says the quiet part out loud: scientific agents have not taken off because "AI for science has a big wet lab problem." Biology is not software. Cells need to grow, instruments emit ugly data, reagents sit on shelves, protocols live in people's hands, and the real work happens across a messy chain of design, execution, observation, and interpretation.
That is a better argument than most "AI Scientist" manifestos make. It moves the conversation away from automated paper generation and toward the actual bottleneck in science: closing the loop between digital reasoning and wet lab execution. Benchling is right that the future system has to connect predictive models, structured data, instruments, robotics, workflows, and expert interfaces.
But read the role assignment carefully. In Benchling's own description, "the human scientist sets a goal." The AI generates a plan, suggests experiment designs, routes work, captures results, and recommends a next step. "At every step, it surfaces key decisions for approval." Then the essay says the human scientist remains "the primary investigator and program leader," because great scientists recognize when something unexpected is worth following.
That is not an AI Scientist. That is an AI Co-Scientist with excellent lab plumbing.
The problem with calling it an AI Scientist is not that it gives the software too much credit. Credit is cheap. The problem is that it misstates the product contract. It tells users, buyers, executives, and eventually regulators to expect replacement where the actual architecture requires collaboration. It makes the impressive parts of the system sound like proof that the human can leave, when the impressive parts only work because the human stays.
Benchling's strongest claims all point in the same direction:
- Model agnosticism matters because scientific judgment includes choosing which tool to trust for this context, not pretending one model has become the scientist.
- Wet lab execution matters because the physical experiment remains the ground truth, not a visualization attached to a chat transcript.
- Structured data matters because science compounds through institutional memory, provenance, and process, not through isolated model outputs.
- Expert interfaces matter because scientific work is visual, precise, contextual, and approval-heavy, not just conversational.
Every one of those claims is a co-scientist claim. The label should match the architecture.
What "AI Scientist" actually produces today
Be fair. The most ambitious projects pointed at this label are not toys. Sakana's pipeline, given a starting codebase, will brainstorm ideas, write code, run experiments, and produce a finished manuscript with figures and references for under $20 per paper, sometimes clearing peer review at lower-tier venues (arXiv:2408.06292). That is real progress, and a few years ago it would have read as science fiction.
But look at where the failures cluster. Independent evaluations of leading "AI Scientist" systems find the same recurring set of problems: hallucinated citations, duplicated figures, manuscripts built by filling out predefined LaTeX templates rather than genuine open-ended discovery, and a habit of "failing to execute" a meaningful fraction of the ideas the system itself proposed (arXiv:2502.14297). The teams building these systems are clear-eyed about it; one of the most prominent recently noted in print that its agent "is susceptible to hallucinations or obvious mistakes, such as generating inaccurate citations." The agent did not fail because the engineers were lazy. It failed because the unsupervised end-to-end frame is harder than it looks, and the missing piece is exactly the thing the name was trying to remove: a person.
The honest summary: today's "AI Scientist" can produce a paper-shaped object. It cannot reliably produce a true sentence about the world.
A category error about what science is for
If you only optimize for paper-shaped objects, you have made a category error about what science is for.
Science is not a paper factory. Papers are an artifact of science, not its purpose. The purpose is the slow accumulation of useful, true, surprising knowledge that humans can stake their reputation on. That is why the citation network exists. That is why retractions matter. That is why the gossip in any departmental hallway is, however unfairly, the most accurate signal of who you can trust.
A system that produces papers without producing accountability does not accelerate that process. It pollutes it. The teams pursuing fully automated paper generation say this themselves in their ethics sections: the ability to "automatically create and submit papers to venues may significantly increase reviewer workload and strain the academic process, obstructing scientific quality control" (arXiv:2408.06292). When the people building the AI Scientist are warning you about the externalities of the AI Scientist, that is worth taking at face value.
There is no academic equivalent of "we'll fix it in the next deploy." The literature is the deploy.
Polanyi's paradox, the part nobody trains on
Now the deeper argument. The reason an AI Co-Scientist is not just an AI Scientist with better marketing is that science depends on a kind of knowledge that does not live in text.
Michael Polanyi, the Hungarian-British physical chemist turned philosopher, gave this idea its tightest formulation in The Tacit Dimension (1966): "We can know more than we can tell" (Polanyi's paradox, Wikipedia). His point was that humans constantly perform tasks they cannot fully describe. A face. A bicycle. A diagnosis. A reaction that "smells off." Polanyi called this tacit knowledge and argued, in his later essay collection Knowing and Being (1969), that all knowledge is "either tacit or rooted in tacit knowledge. A wholly explicit knowledge is unthinkable." There is no escape from the personal.
This is not abstract. Spend a week shadowing a working lab and you will collect a list:
- The PI who knows, just by looking at a Western blot, that the loading is off.
- The postdoc who refuses to trust runs from the new sequencer "until it has been on for a week."
- The grad student who throws out a perfectly clean p = 0.04 because the cell line "has been weird since the move."
- The collaborator whose data you cross-check, and the one whose data you don't.
- The reviewer who can smell a fabricated dataset at fifty paces and could not, if you asked, tell you why.
None of that is in the literature. None of it is in the model weights. It moves through people, by apprenticeship, over years, and it is the actual substrate of scientific judgment.
Polanyi's harder line, the one that should be on a poster in every AI lab: "Our reliance on the validity of a scientific conclusion depends ultimately on a judgment of coherence... a qualitative, nonformal, tacit, personal judgment." A model can render answers. It cannot render that judgment. Anyone telling you otherwise has either not built one or not done science.
This is what the co- in co-scientist is protecting. It is the line beyond which we are not yet willing to go, because we know what is on the other side and we know who has to stand there.
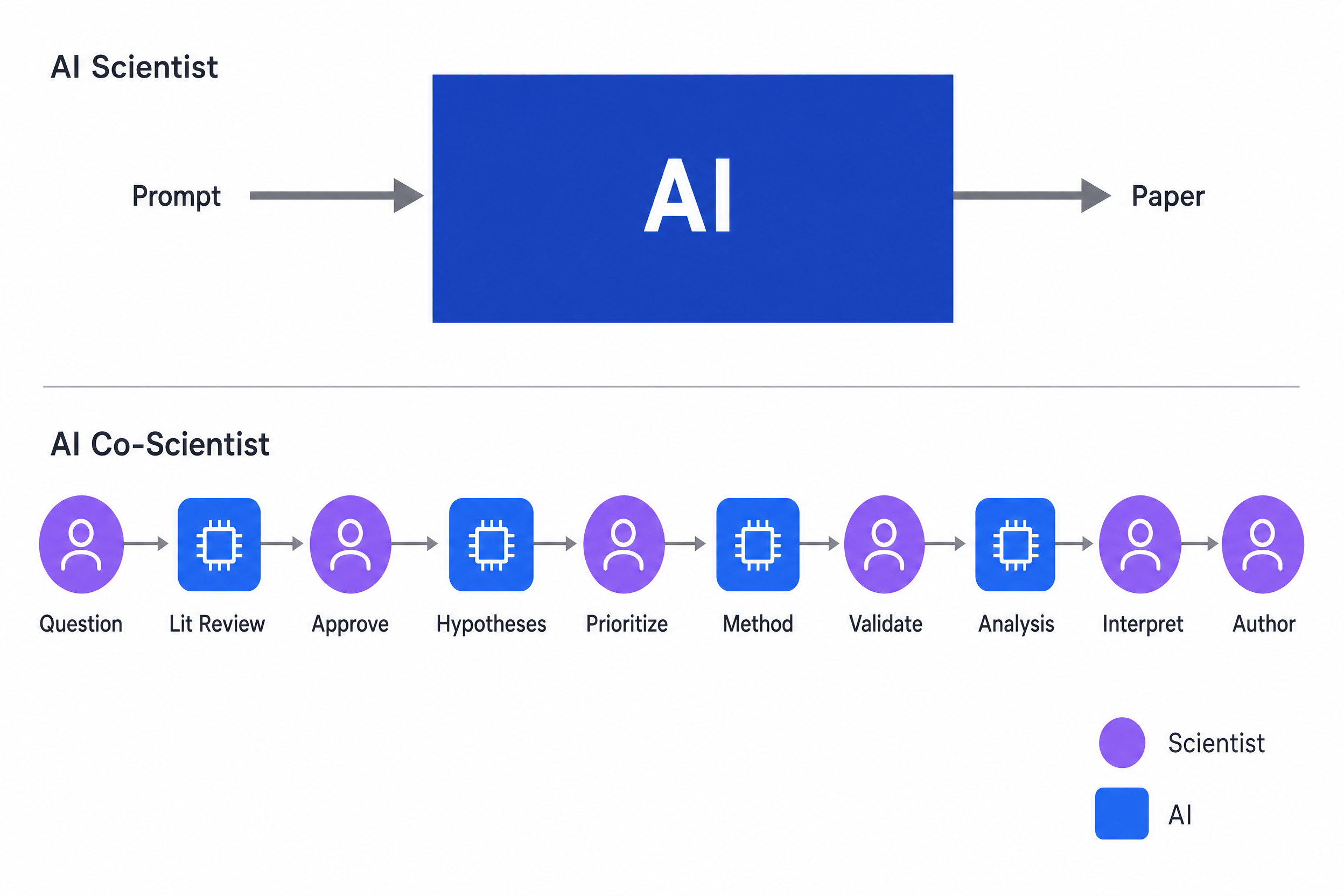
Two architectures, two beliefs about what science is.
The lesson the AlphaFold headlines missed
Here is the anecdote that keeps me grounded. On 9 October 2024, the Royal Swedish Academy of Sciences awarded the Nobel Prize in Chemistry. Half of it went to David Baker for computational protein design. The other half went jointly to Demis Hassabis and John Jumper for "protein structure prediction" (Nobel press release).
The prize did not go to AlphaFold.
Read that sentence again. Arguably the most consequential AI system in the history of biology was on the bibliography. Three humans were on the medal. The Nobel Committee, on the rare occasion it gets to pick a piece of language carefully, picked humans.
In his Nobel lecture on 8 December 2024, Hassabis titled the talk "Accelerating scientific discovery with AI" (lecture PDF). Not "Replacing scientific discovery." Not "Discovering science with AI alone." Accelerating. The verb matters. He went on to walk through the data dependency at the heart of AlphaFold's success: "after decades of experimental work ~170,000 structures had been determined and collated in Protein Data Bank (PDB), an incredible resource that we used as a starting point to train AlphaFold." That sentence does more philosophical work than most papers manage in twenty pages.
AlphaFold is not the replacement of structural biology. It is the concentration of fifty years of structural biology into a tool that every biologist now uses to start their next experiment. It sits between humans and humans. The crystallographers and cryo-EM groups whose data trained the model are upstream of it. The structural biologists who now use it to design the next experiment are downstream of it. There is an AI in the middle, and it is genuinely doing extraordinary work, and it is also, structurally, in the middle.
That is the co-scientist pattern in its most literal form.
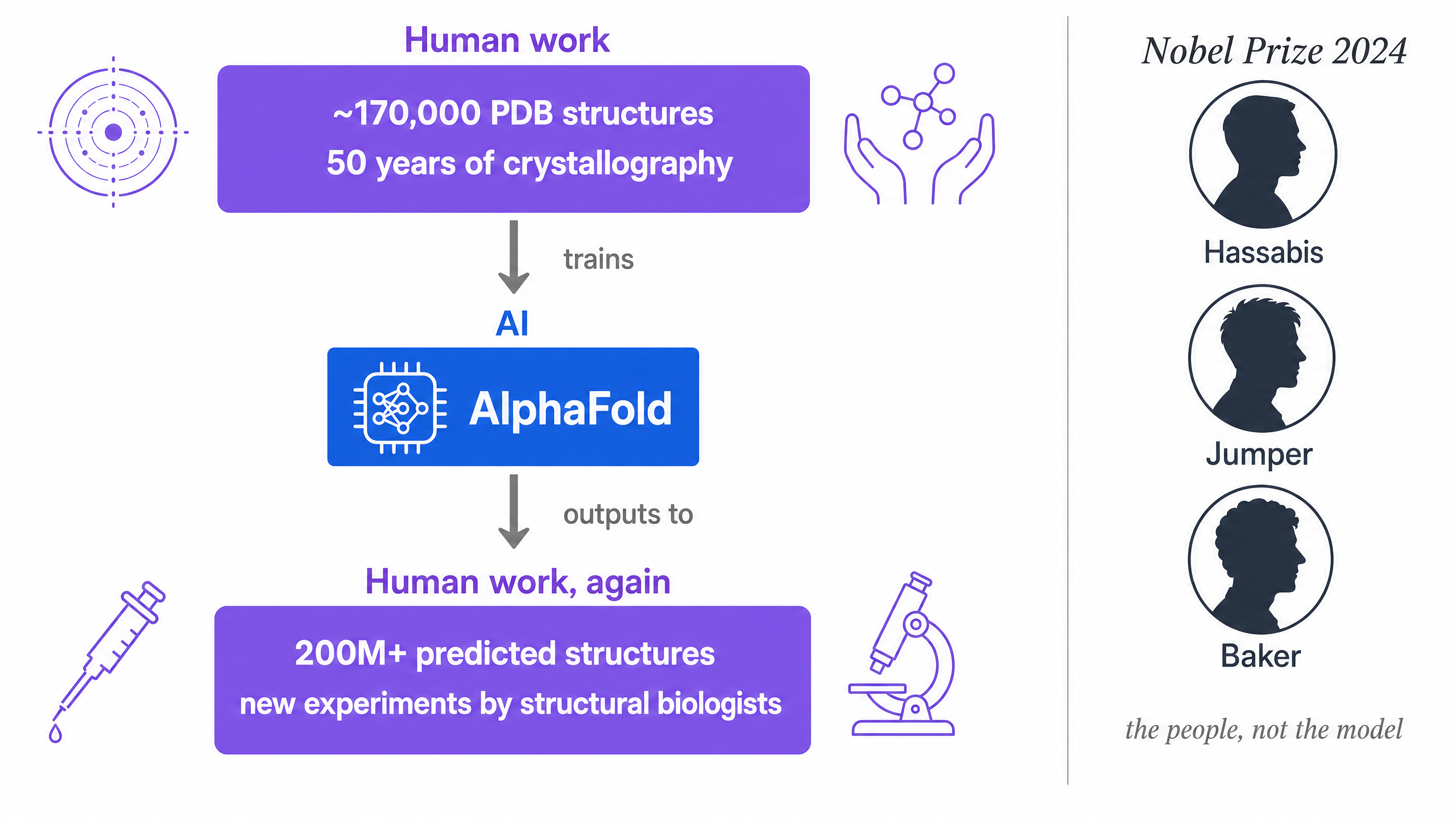
AlphaFold sits between humans and humans. That is the co-scientist pattern.
Even DeepMind says co-scientist. So does CMU. So does GitHub.
If you think this is a small startup's positioning trick, look at where the rest of the industry has landed.
On 19 February 2025, Google DeepMind launched what it explicitly named an "AI co-scientist," built on Gemini 2.0 (Google Research, arXiv:2502.18864). The first sentence of the announcement positioned it as "a virtual scientific collaborator." The official Google Keyword post added, in case anyone missed it: "AI co-scientist is a collaborative tool to help experts gather research and refine their work, it's not meant to automate the scientific process" (Google Keyword).
The system itself is built that way. It is a coalition of specialized agents (Generation, Reflection, Ranking, Evolution, Proximity, Meta-review, Supervisor) designed to interact with a human researcher, not to replace one. Its early validated outputs include drug repurposing for acute myeloid leukemia (validated in cell lines) and AI-suggested epigenetic drug candidates for liver fibrosis (validated in human hepatic organoids by collaborators at Stanford), with the latter producing a 2025 paper in Advanced Science (Guan et al., 2025). The system was rolled out through a Trusted Tester Program, working with a small set of principal investigators. None of these design decisions are accidental.
This is not just one company's bet. CMU's group named their autonomous chemistry agent Coscientist (Boiko et al., Nature 2023). GitHub picked Copilot, not "Coder," and that single naming choice arguably did more to drive adoption than any feature on the roadmap. The AI sits in the right seat, not the left.
When the most capable AI labs in software and in science independently reach for the same hyphen, that is not marketing softness. That is design discipline.
The steelman: isn't co-scientist just a softer brand?
The strongest objection is that "co-scientist" is a kind of corporate humility theater. The AI is doing the work; the marketing puts a person in the picture for legal and emotional cover; one or two more model releases and we'll quietly drop the hyphen.
I do not think that is right, for three reasons.
First, names are specs. A team that says "AI Scientist" optimizes for autonomy benchmarks: how many papers, how cheap, how unattended. A team that says "AI Co-Scientist" optimizes for the things that actually let a researcher use the system on Tuesday morning: inspectable trajectories, citation grounding, peer-review passes that flag weak claims, escape hatches everywhere, audit logs that survive a methods-section interrogation. Those are different products, built by teams with different KPIs.
Second, co- forces concrete design choices. It forces you to ship a UI where the human can stop, edit, and resume. It forces you to make the agent's reasoning legible, not just its output. It forces you to treat the policy file (the YAML the human wrote) as authoritative over the model's preferences. None of this is solved by adding a person to a marketing illustration after the fact.
Third, eventually, somebody might earn the right to drop the hyphen. Some narrow domain. Some genuinely closed loop. When that happens, we will cheer it. But we are not going to pre-name it that way and force every working scientist to act as if the future has already arrived. The cost of that pretense lands on the person whose career depends on the manuscript being correct.
The hyphen is not soft. It is a load-bearing constraint, and you can feel it in the product when it is missing.
Where the human stays in front, in practice
Saying we build a co-scientist would be empty if we could not point at where the human shows up in the actual product. Three places, each tied to something we have already shipped.
Question-picking is the human's job. When we walked through what an autonomous agent can do for early research planning (the PhD-proposal example), the system surveyed seven technology areas, identified five gaps, and produced a 26-page proposal in 45 minutes. It took us months to internalize the right takeaway from that result. The agent does the literature compression. The researcher decides which gap is worth four years of their life. The system writes the menu. The human orders.
Tacit lab knowledge is encoded as Skills, not absorbed. When we wrote about Agent Skills, the whole architectural argument was that procedural knowledge should live in Markdown files written by the people who actually have it, not in model weights. The PI writes the SKILL.md that says "in our lab, we cap pct_counts_mt at 20% and we always cross-reference against the internal DFT database before publication." That sentence is the whole game. It is the place where a Tuesday-morning lab convention becomes part of how the AI behaves.
Authority is bounded by policy, not by vibes. When we wrote about pairing OpenShell with Scientific Agent Skills, the design pattern was: skills are the "what," policy is the "where," and when they disagree, policy wins. The agent's blast radius is whatever YAML the human wrote. This is unromantic, and that is the point. We do not want romance with our autonomous agents on patient data.
There is a fourth, less glamorous place the human shows up: on the byline. Every K-Dense Web session is inspectable, every output is grounded in citations the user can click, every claim has provenance. That is not a fancy feature. It is the bare minimum for a tool whose outputs are going to end up in someone's grant proposal, someone's IRB submission, someone's manuscript. The work has to be defensible, and the defense has to be done by a person.
The dividing line
Here is the dividing line, stated as plainly as I can.
The AI's job is the boring 90%: speed, breadth, recall, tireless iteration, formatting, execution, the fourteenth permutation of the regression that you, frankly, were going to skip. Outsource it. It will do it well. It will do it cheaply. It will do it at 2 a.m. while you sleep.
The scientist's job is the part that matters: choosing the question, exercising taste, knowing the lab's tacit conventions, deciding which result to trust, taking responsibility, signing the final draft. None of that is bottlenecked by speed. All of it is bottlenecked by judgment.
The hyphen is the contract between those two jobs. It is also, not incidentally, what makes the partnership safe.
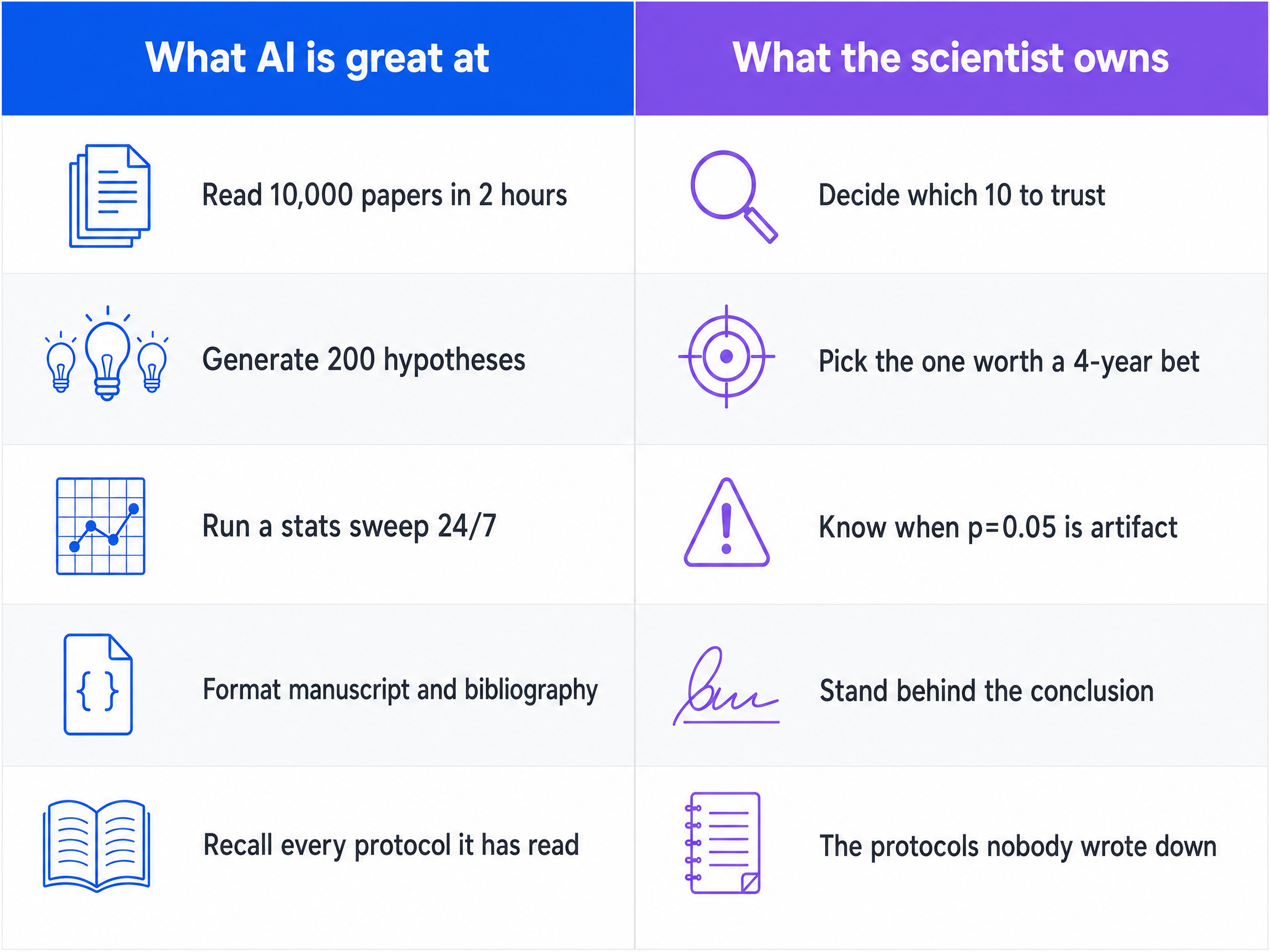
A division of labor, not a hierarchy.
What this changes about your day
If you are reading this as a working scientist, the practical implication is short.
You should not be doing things a co-scientist is willing to do. Stop reading the seventeenth review article on a side-quest mechanism. Stop hand-tuning the boilerplate plotting code you have written ten times. Stop manually reformatting bibliographies. Stop wading through methods sections to extract the one parameter you needed. A co-scientist will do every one of those things in minutes, will do them visibly, and will hand you back the parts that are actually yours: the question, the priorities, the interpretation, the call.
You should be doing more of the things only you can do. Pick harder questions. Talk to more people. Hold a stronger opinion about what the right next experiment is. Push back when the AI's hypothesis is plausible but boring. Read your own data with the slightly suspicious affection of someone who has made every mistake before. Bring the full weight of your reputation to the conclusion.
The science is yours. The tedium isn't. That is the trade we built K-Dense Web around.
Why we chose the name before we shipped a feature
We picked "AI Co-Scientist" before we had a product. We picked it on a whiteboard in a small room, and we picked it because the alternative would have made us build something we did not want to ship.
If we had said "AI Scientist," we would have spent the first year of the company chasing autonomy benchmarks, racing to remove humans from the loop, optimizing for the demo. We would have built something that, at its best, gets quoted in TechCrunch and, at its worst, contributes to the credibility crisis that working scientists already feel in their bones.
Instead, we chose a name that put the scientist in the sentence. Then we built the product around the name. The result is a system whose strongest claim is not that it does science by itself. The strongest claim is that it makes a person doing science noticeably better, in less time, with their reputation intact.
We will keep the hyphen. We hope you keep yours too.
Try it for yourself: Get started on K-Dense Web. Pay-as-you-go pricing, no autonomy theater.
Questions, disagreements, war stories from your own bench? Email contact@k-dense.ai.
Related reading: