
K-Dense is the world leader in scientific skills for AI agents, with production systems that turn frontier models into reproducible scientific workflows across biology, chemistry, materials, and data analysis. In benchmarking the NVIDIA NIM, we sought to answer if packaging those models as agent skills makes a measurable difference when an AI agent has to choose the right API, call it correctly, validate the output, and chain several tools into a useful scientific workflow.
These NVIDIA NIM skills are already part of K-Dense BYOK for teams that want to run agentic scientific workflows with their own NVIDIA credentials, and they are coming soon to K-Dense Web. That made this study practical as well as methodological: we wanted to know not only whether the skill layer is elegant, but whether it changes reliability and cost for real users.
That distinction matters. A skeptical reader can reasonably ask whether an agent skill is just documentation with a name. If the answer is yes, then a fair baseline is simple: paste the relevant docs into the prompt and let a capable model figure it out. If the skill still helps under that comparison, then it is doing something more than carrying information.
We ran that test directly. Across about 830 controlled execution runs against hosted NVIDIA NIM APIs, using three Claude model tiers and 10 NIM skills, the result was clear and more interesting than a simple win-loss story. The skills did not make the underlying scientific models more accurate, and they did not beat the all-docs-in-context baseline on single-call success. They won on routing, cost, scale, and reliability, especially when the base model was weaker or the workflow required several tools in sequence.
The Short Version
The benchmark compared four conditions. In baseline, the agent had no skill and no extra docs. In docs, it received the one relevant API reference, which is a favorable control because the harness pre-selected the right document. In docs_all, it received all 10 API references with no pre-selection, which is the honest "just paste the docs" alternative. In skill, the NIM skills were available through progressive disclosure, so only descriptions were resident and the detailed guidance loaded on demand.
The headline is that skills are not magic model upgrades. When any arm reached the same valid NIM call, the scientific output was essentially the same, because the same NVIDIA model served the request. ProteinMPNN native-sequence recovery stayed around 40 percent across arms and model tiers, matching the expected range. The skill's job was not to create scientific accuracy, it was to reliably deliver the agent to the right scientific computation.
That delivery layer mattered in four ways. First, skills prevented endpoint hallucination on non-obvious APIs. Second, they kept resident context flat instead of paying a large documentation tax on every prompt. Third, they let cheaper models succeed on hard calls that their baselines often missed. Fourth, they improved malformed-input handling on weaker models that otherwise failed confidently.
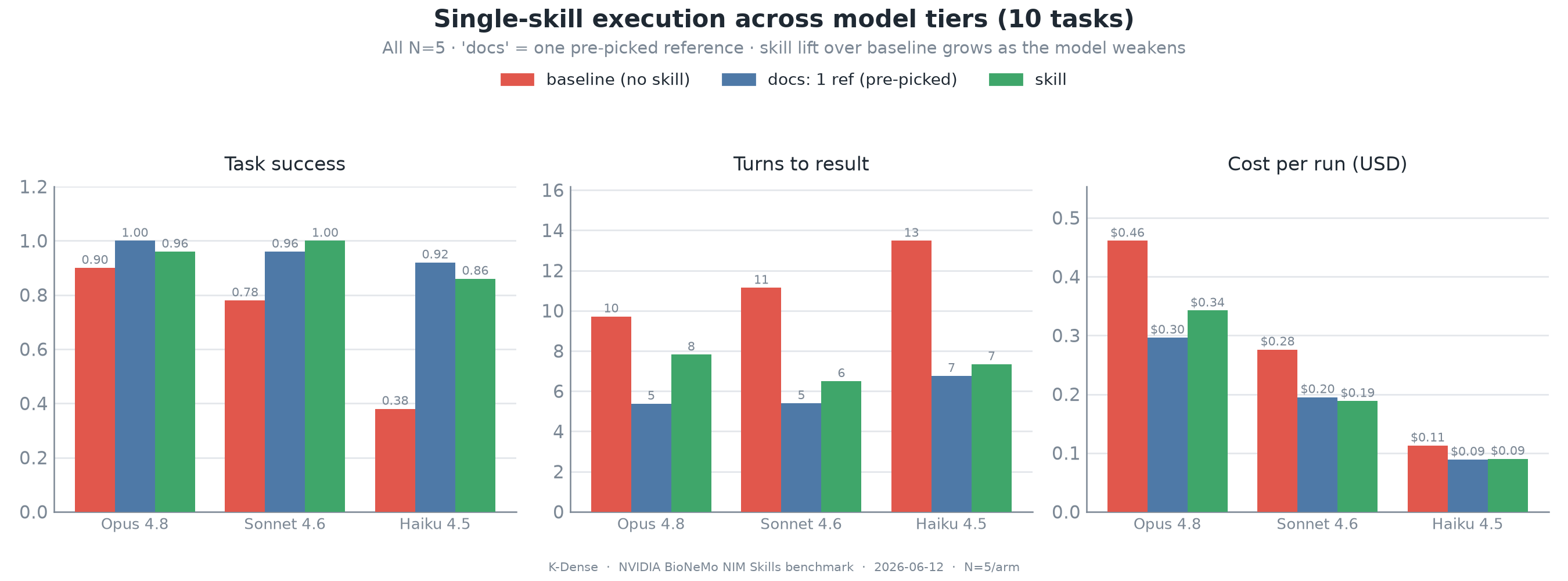 Figure 1. Single-skill macro results. Opus is near ceiling on success, but the skill reduces turns and cost versus baseline, and its success lift grows on weaker models.
Figure 1. Single-skill macro results. Opus is near ceiling on success, but the skill reduces turns and cost versus baseline, and its success lift grows on weaker models.
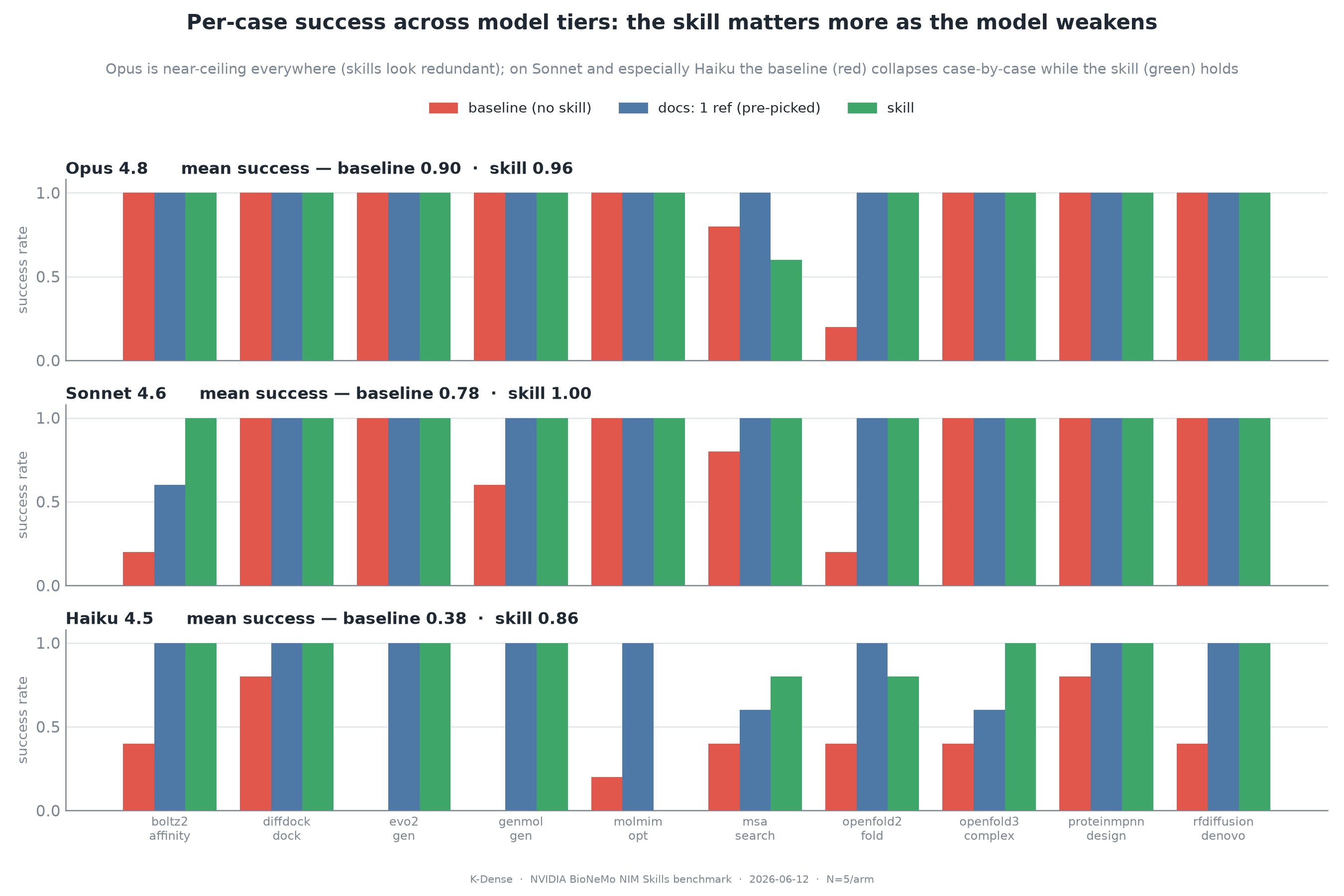 Figure 2. Per-case success across model tiers. On Opus, the main failure is the non-obvious OpenFold2 endpoint. On weaker models, baseline failures spread across more cases.
Figure 2. Per-case success across model tiers. On Opus, the main failure is the non-obvious OpenFold2 endpoint. On weaker models, baseline failures spread across more cases.
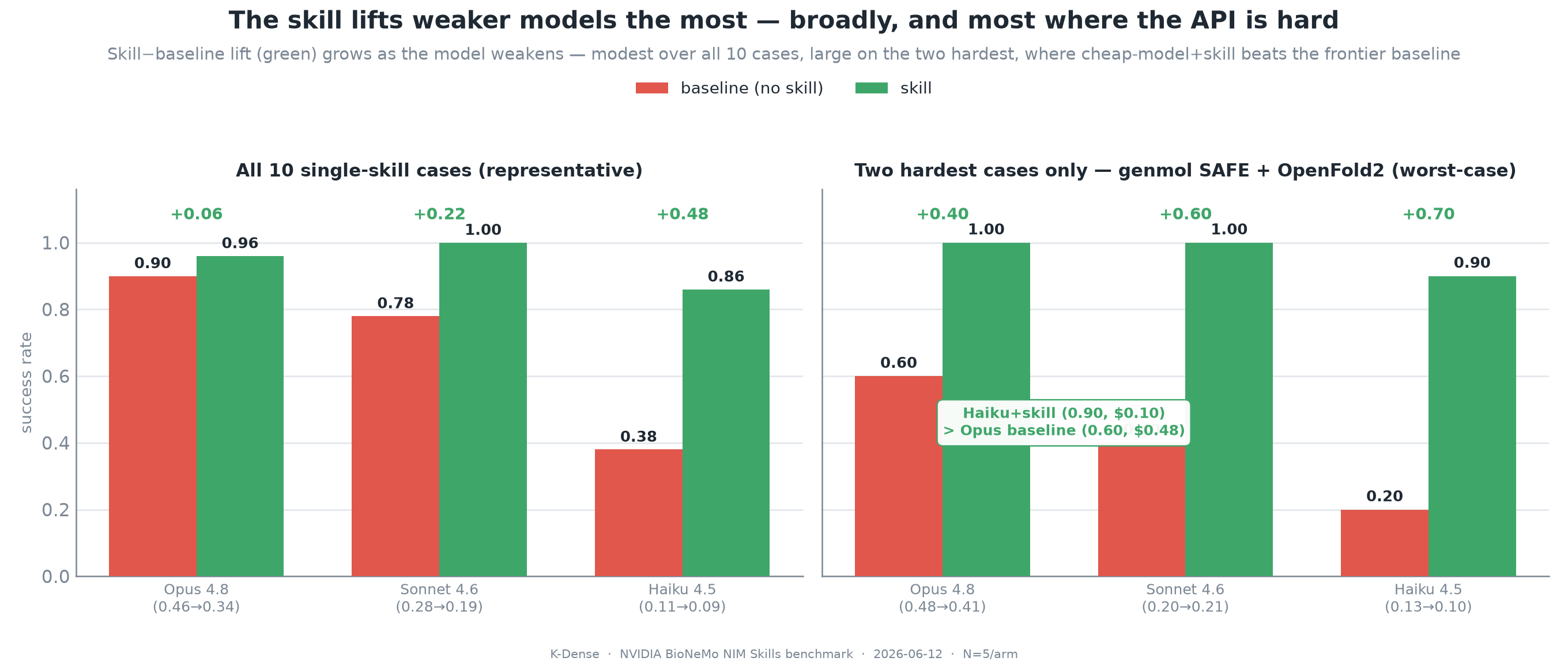 Figure 3. Skill lift grows as the base model weakens. The full 10-case view shows the representative effect, while the two-case hard subset isolates GenMol SAFE notation and the non-obvious OpenFold2 endpoint.
Figure 3. Skill lift grows as the base model weakens. The full 10-case view shows the representative effect, while the two-case hard subset isolates GenMol SAFE notation and the non-obvious OpenFold2 endpoint.
What We Tested
The system under test was Claude Code in headless mode, calling hosted NVIDIA NIM endpoints through normal HTTP requests authenticated with an NGC API key. The skills covered 10 NIM capabilities: Boltz-2, OpenFold2, OpenFold3, DiffDock, ProteinMPNN, RFdiffusion, GenMol, MolMIM, Evo 2, and MSA-Search. These are not toy APIs. They expose real biomolecular workflows, including structure prediction, docking, molecular generation, inverse folding, de novo backbone design, genomic sequence generation, and MSA construction.
Every execution experiment was run across three model tiers: Opus 4.8, Sonnet 4.6, and Haiku 4.5. We used N=5 per case, arm, and model cell. That is still a modest sample size, and we treat confidence intervals accordingly, but it is enough to distinguish large, consistent effects from saturated near-ties. In total, the benchmark covered triggering, single-skill execution, docs controls, component ablations, malformed-input robustness, ground-truth recovery and folding checks, and two multi-skill pipelines.
The primary success definition was deliberately operational. A run succeeded if the agent reached the correct NIM endpoint and produced a validator-passing artifact, such as a valid mmCIF, PDB, SDF, SMILES, A3M, FASTA, or sequence output. This kept the benchmark objective. We scored HTTP logs, tool calls, and artifacts rather than asking an LLM judge whether an answer looked good.
Skills Fire Conservatively
Before measuring execution, we first asked whether the skills trigger at the right time. This matters because a skill that fires too often is not useful, even if it works when explicitly invoked. Across positive prompts and adversarial negatives, specificity stayed perfect at every model tier: zero false triggers, including prompts that named scientific concepts but did not ask the agent to run a tool.
The tradeoff was recall. Opus triggered the right skill on 95 percent of positive prompts. Sonnet dropped to 73 percent, and Haiku dropped to 32 percent. In other words, weaker models under-fire on terse prompts, but they do not mis-fire. That is a much better failure mode than calling an unrelated biomolecular API, because a missed trigger usually means the agent asks for more input or does nothing destructive.
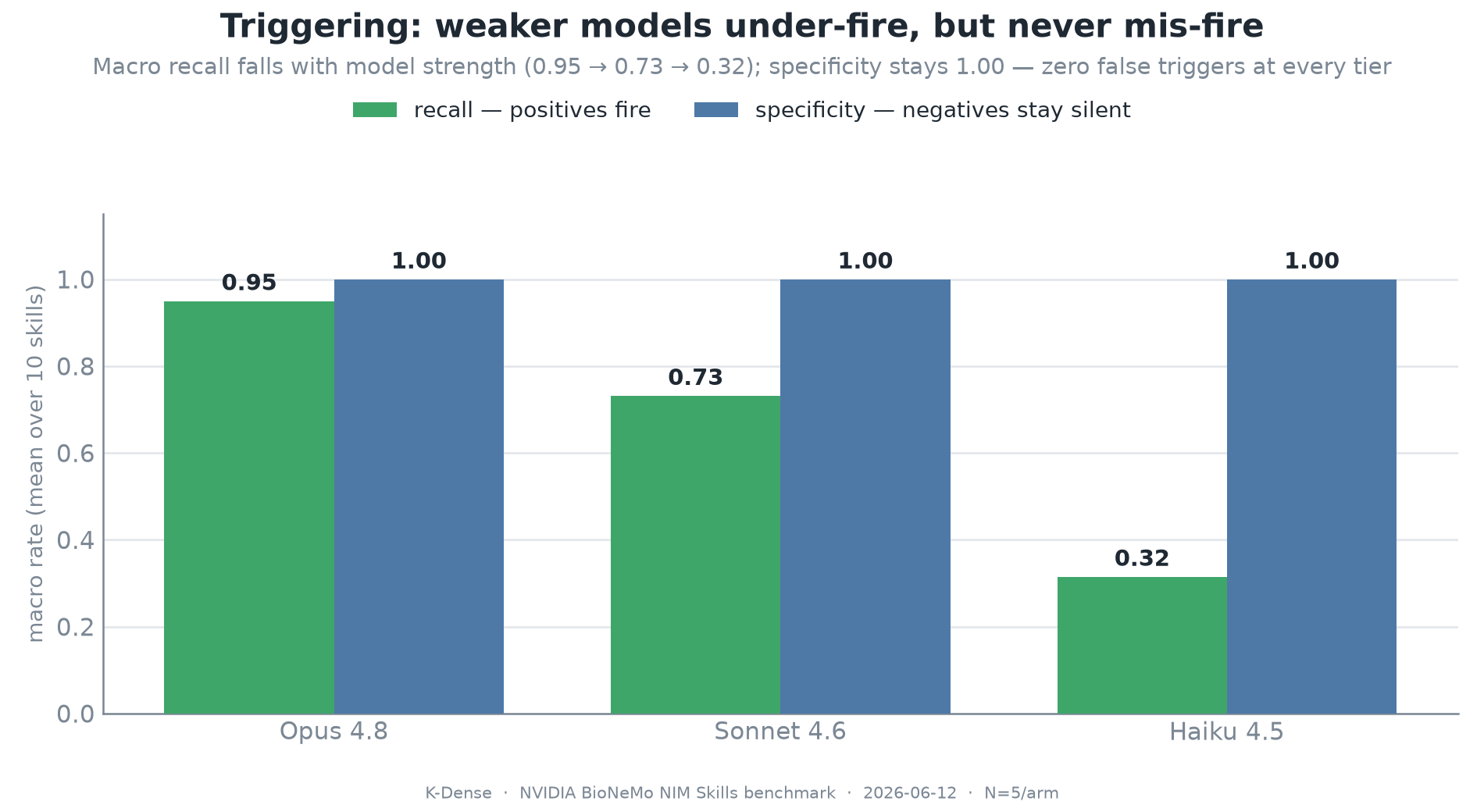 Figure 4. Triggering is conservative. Specificity stays at 1.00 across models, while recall falls from Opus to Sonnet to Haiku.
Figure 4. Triggering is conservative. Specificity stays at 1.00 across models, while recall falls from Opus to Sonnet to Haiku.
With all 10 skills loaded, the routing sweep told the same story. The agent never selected an unrelated tool and stayed silent on all out-of-scope prompts. The remaining misses were mostly defensible: folding tools overlap in capability, and prompts without a sequence, structure, or molecule often led the agent to ask for missing inputs rather than making up a run.
On Easy Endpoints, Strong Models Already Know What To Do
On the full 10-case single-skill benchmark, Opus baseline performance was already high. The no-skill baseline succeeded on 90 percent of runs, the one-doc oracle succeeded on 100 percent, and the skill succeeded on 96 percent. The paired bootstrap skill-minus-baseline success delta on Opus was only +0.06, with a confidence interval that included zero. A frontier model already knows many public NIM APIs, so the skill does not create a large success gap on endpoints that are easy to infer.
The efficiency gap was more stable. On Opus, the skill reduced average turns from 9.7 to 7.8 and average cost from $0.46 to $0.34 per run versus baseline. That is a 20 percent turn reduction and a 26 percent cost reduction, even when success was near ceiling. The one-doc docs arm was cheaper still because the benchmark harness had already done the routing work by picking the right document in advance.
| Model | Arm | Task Success | Endpoint Correct | Turns | Cost per Run |
|---|---|---|---|---|---|
| Opus 4.8 | baseline | 0.90 | 0.94 | 9.7 | $0.46 |
| Opus 4.8 | docs | 1.00 | 1.00 | 5.4 | $0.30 |
| Opus 4.8 | skill | 0.96 | 1.00 | 7.8 | $0.34 |
| Sonnet 4.6 | baseline | 0.78 | 0.92 | 11.1 | $0.28 |
| Sonnet 4.6 | docs | 0.96 | 1.00 | 5.4 | $0.20 |
| Sonnet 4.6 | skill | 1.00 | 1.00 | 6.5 | $0.19 |
| Haiku 4.5 | baseline | 0.38 | 0.40 | 13.5 | $0.11 |
| Haiku 4.5 | docs | 0.92 | 1.00 | 6.8 | $0.09 |
| Haiku 4.5 | skill | 0.86 | 0.88 | 7.3 | $0.09 |
This table is the first place where the honest shape of the benchmark appears. On a strong model, skills are mostly an efficiency layer. On weaker models, they become a reliability layer. Sonnet moved from 0.78 baseline success to 1.00 with the skill, and Haiku moved from 0.38 to 0.86. The model got smaller, but the skill carried more of the operational burden.
The Clean Routing Win Was OpenFold2
The most diagnostic single case was OpenFold2. The true endpoint path is not simply "openfold2." It is predict-structure-from-msa-and-template, which is exactly the kind of non-obvious API detail that causes agents to hallucinate plausible but wrong calls.
That is what happened. Across five Opus baseline runs, the agent tried a bare OpenFold2 path, a truncated path, and once even treated the output file path as an endpoint. It found the correct endpoint only two times and completed successfully once. The skill and docs arms hit the exact path five out of five times.
That matters because this is the failure that should worry tool providers. A strong general model can often infer common API shapes, but it can also confidently invent plausible endpoints where the true route is idiosyncratic. The skill solved that class of problem by putting the exact route in the agent's working procedure, not by making the underlying model more scientifically capable.
Skills Deliver Accuracy, They Do Not Create It
One of the most important negative results is that the skill did not improve scientific accuracy once a valid call was reached. ProteinMPNN native-sequence recovery stayed around 40 percent across arms and models. That is the expected result, because every arm called the same NVIDIA model behind the API.
This is not a weakness of the skill. It is a boundary on the claim. The skill is a conduit and control layer, not a new predictor. If the underlying NIM produces a good structure, sequence, or docked pose, the skill can help the agent reach that computation and check that the artifact is valid. If the underlying model is wrong, the skill cannot make it right.
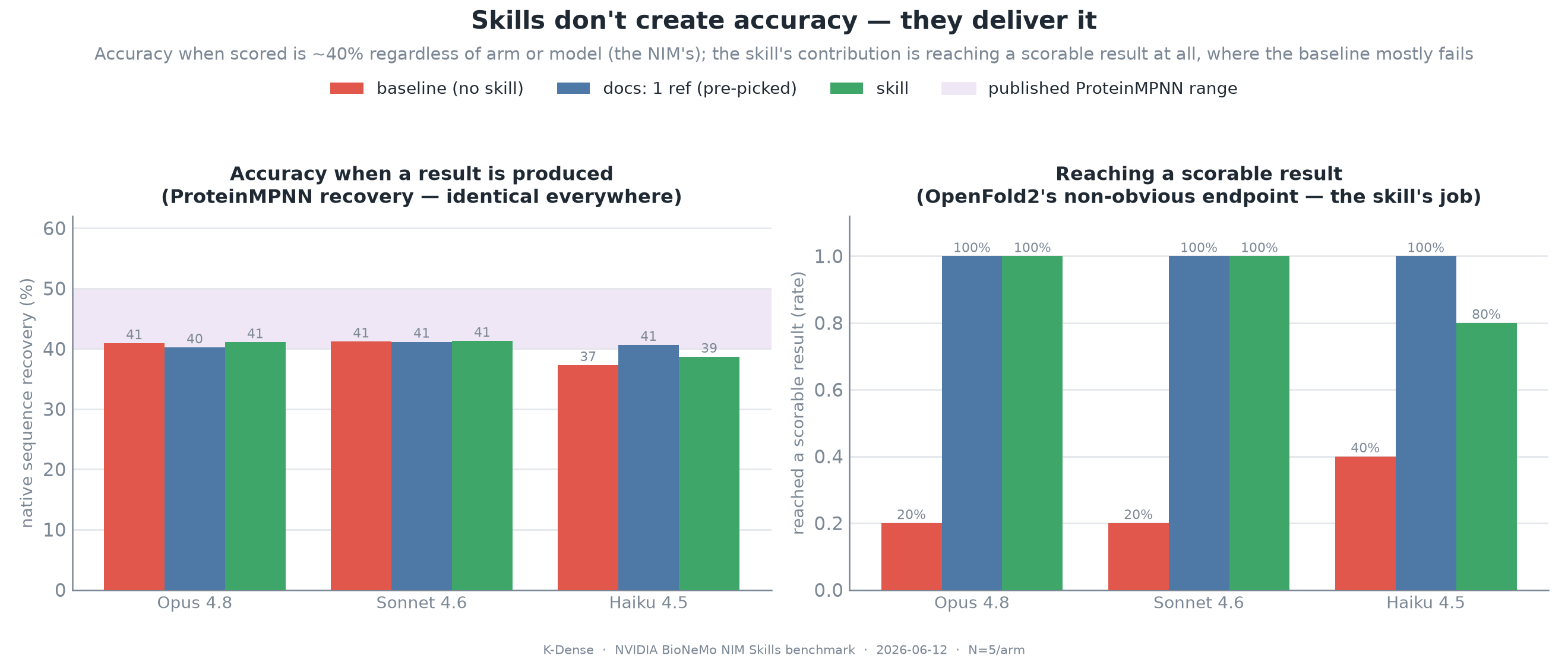 Figure 5. Skills deliver the model's accuracy, they do not create it. Recovery stays flat when scored, while reach rate changes sharply on the hard OpenFold2 endpoint.
Figure 5. Skills deliver the model's accuracy, they do not create it. Recovery stays flat when scored, while reach rate changes sharply on the hard OpenFold2 endpoint.
The useful decomposition is reach rate times accuracy. Accuracy when scored belongs to the NIM. Reach rate belongs to the agent workflow. On OpenFold2, the baseline often failed to reach a scorable result at all, while the skill got there far more reliably. That is how the skill increases realized scientific output without changing the scientific model.
The Real Docs Comparison
The most important control was docs_all. The one-doc docs arm is useful, but it is not the real alternative to skills because it assumes a human or harness has already chosen the correct document. In a real deployment with many tools, the agent does not get oracle routing. It either gets all the docs in context, retrieves the right one somehow, or uses a skill-like mechanism that can trigger and load guidance as needed.
On the hard two-case subset, docs_all recovered the same single-skill success as the skill at every tier. Opus and Sonnet both reached 1.00, while Haiku reached 0.90 in both arms. That means the skill did not beat pasted documentation on single-call success. The win was cost and scale. At equal success, docs_all was 39 percent more expensive than the skill on Opus, 60 percent more expensive on Sonnet, and 45 percent more expensive on Haiku.
| Model | Baseline | Skill | Docs All | Docs All Cost vs Skill |
|---|---|---|---|---|
| Opus 4.8 | 0.60 ($0.48) | 1.00 ($0.41) | 1.00 ($0.57) | +39% |
| Sonnet 4.6 | 0.40 ($0.20) | 1.00 ($0.21) | 1.00 ($0.34) | +60% |
| Haiku 4.5 | 0.20 ($0.13) | 0.90 ($0.10) | 0.90 ($0.15) | +45% |
This is the answer to "is a skill just docs?" The information content can be equivalent, but the mechanism is not. Dumping all docs into context makes the model pay for every reference on every prompt. A skill keeps only the trigger descriptions resident and loads the heavy material only when it is needed.
Progressive Disclosure Is the Scaling Mechanism
The token-footprint measurement made this concrete. With 10 skills, the always-resident skill descriptions were about 768 tokens. A task that fired one skill loaded about 3,645 tokens total, including the description, SKILL.md, and one reference. The docs_all condition kept about 12,910 tokens in context on every prompt.
That is a 16.8x always-resident context difference at only 10 APIs. More importantly, the shape is different. Skills stay roughly flat as the API surface grows, while pasted docs grow linearly. At 50 APIs, dumping every reference into context is not just expensive, it becomes operationally awkward or impossible. Progressive disclosure is the part of the skill architecture that makes many-tool systems tractable.
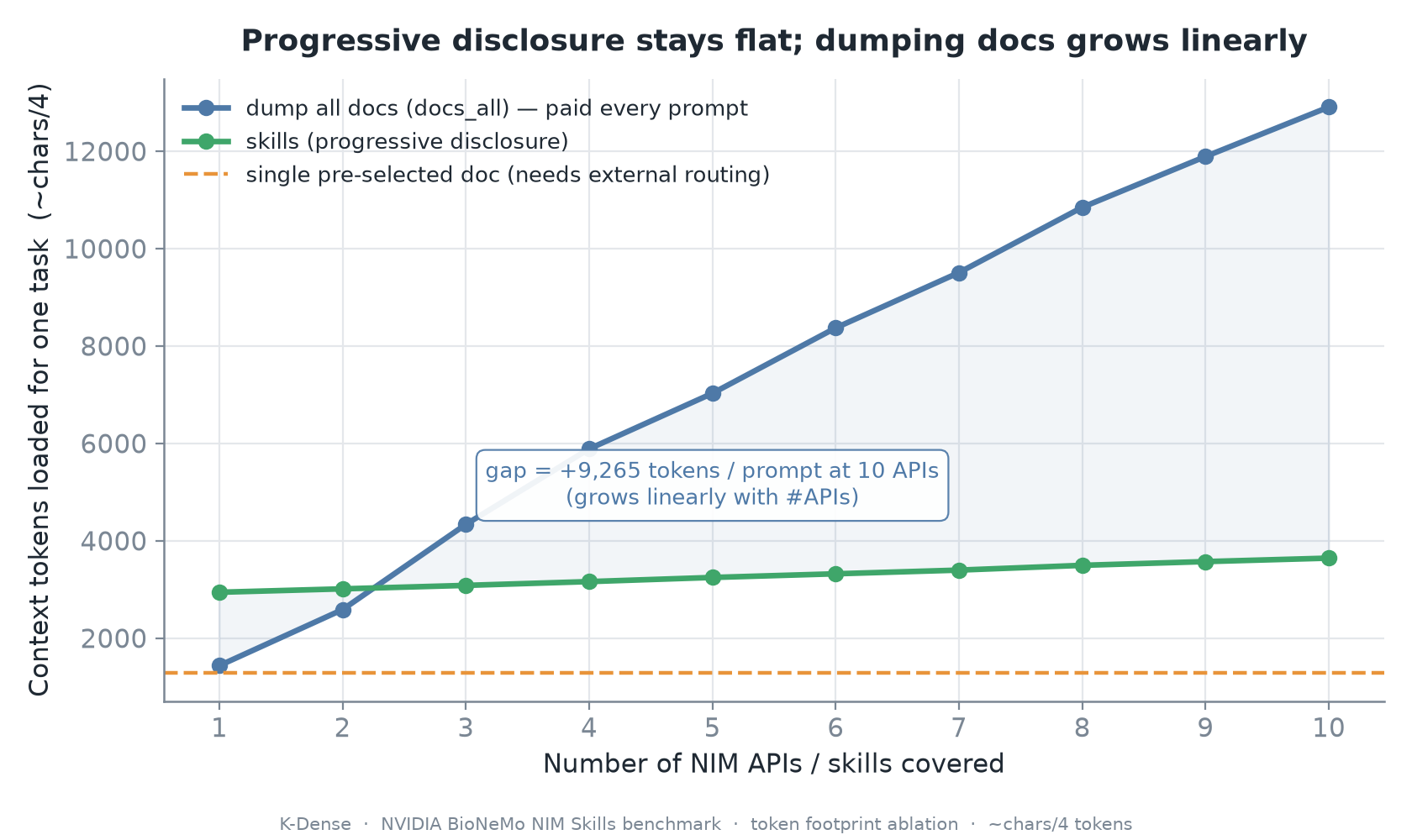 Figure 6. Token footprint. The exact counts use a chars-over-four heuristic, but the important result is the flat skill curve versus the linear docs_all curve.
Figure 6. Token footprint. The exact counts use a chars-over-four heuristic, but the important result is the flat skill curve versus the linear docs_all curve.
This also explains why the one-doc control is not a deployment strategy. A single pre-selected document is cheap because the routing problem has already been solved outside the model. The skill internalizes that routing step, while avoiding the all-docs tax.
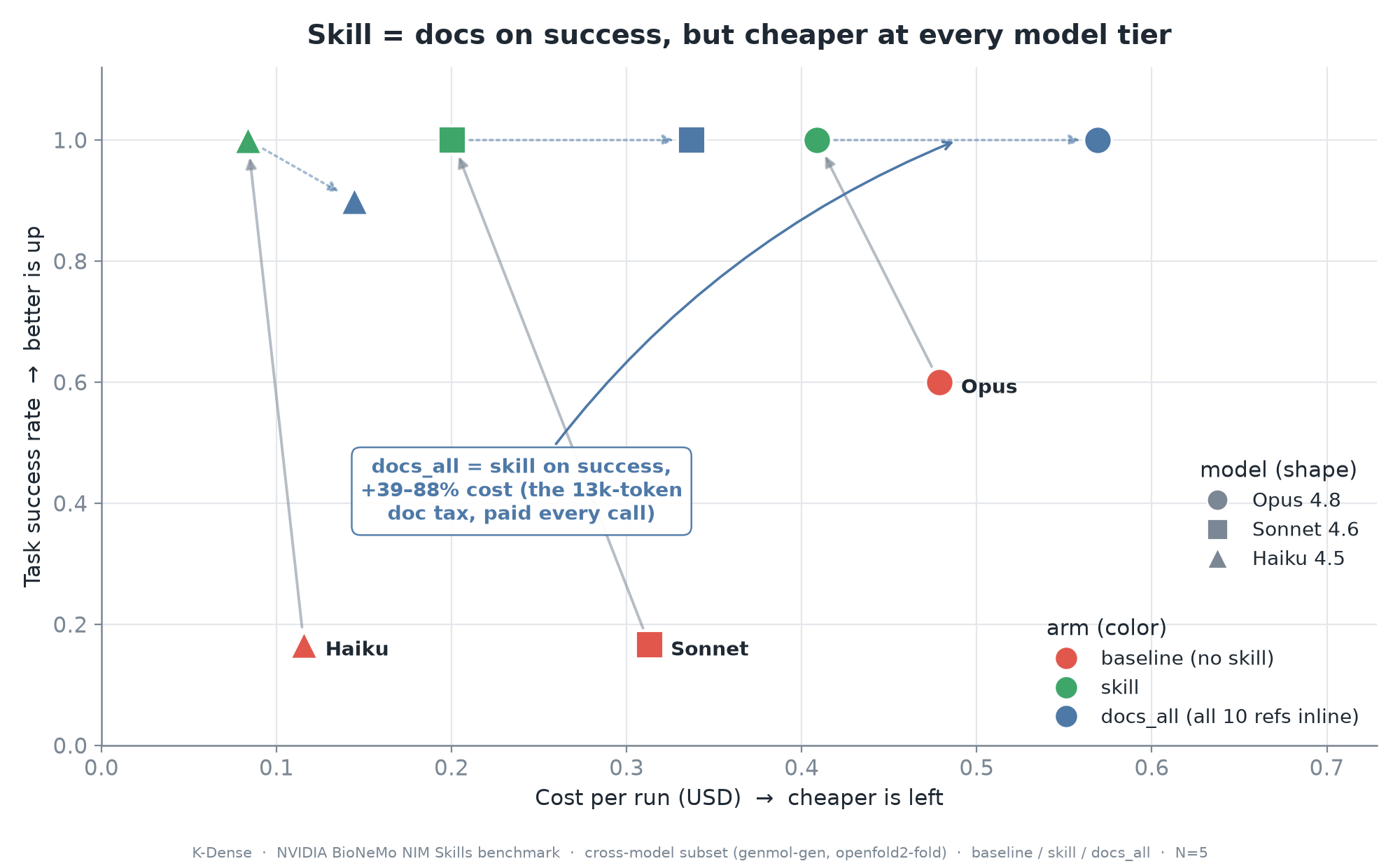 Figure 7. Cost versus success. In single-skill hard cases, skill and docs_all reach the same height, but the skill sits to the left, meaning equal success at lower cost.
Figure 7. Cost versus success. In single-skill hard cases, skill and docs_all reach the same height, but the skill sits to the left, meaning equal success at lower cost.
The Skill Helps Weaker Models Most
The cross-model result was the clearest practical story. Over all 10 single-skill cases, skill-minus-baseline success lift increased as the base model weakened: +0.06 on Opus, +0.22 on Sonnet, and +0.48 on Haiku. On the two hardest cases, GenMol SAFE notation and OpenFold2 routing, the lift was even larger: +0.40, +0.60, and +0.70.
That produced the benchmark's sharpest economic result. On those hard cases, Haiku 4.5 with the skill reached 0.90 success at $0.10 per run, while Opus 4.8 baseline reached 0.60 success at $0.48 per run. A roughly five-times cheaper model became more reliable than the frontier baseline on the cases where tool knowledge mattered most.
There is an important caveat. This cost inversion is hard-subset specific, not a universal statement. Across all 10 cases, Opus baseline still beat Haiku with skill, 0.90 versus 0.86, because the easy cases were already easy for Opus. The durable claim is narrower and stronger: a skill lets a cheaper model clear hard operational calls that a stronger model may otherwise fumble.
What Part of the Skill Matters?
We also ran component ablations. The skill_noref arm kept only the SKILL.md body, removing detailed references. The skill_noval arm kept references but removed validation guidance. These variants let us ask whether the benefit came from deep documentation, validation content, or the routing overview itself.
For clean-input success, the routing overview was the active ingredient. On OpenFold2, stripping all references still recovered the full skill's success on Opus and Sonnet, moving from baseline 1/5 to 5/5. On GenMol, the SKILL.md-only version also fixed Haiku's SAFE-notation failure. Detailed references did not add measurable clean-input success on top of the routing guidance.
That does not mean the references are useless. It means their value shows up under different conditions. The detailed validation guidance mattered most when the input itself was malformed and the base model was weak.
Curation Shows Up on Malformed Inputs
To test curation, we fed the agents three malformed inputs: ordinary SMILES where GenMol expected SAFE notation, lower-case DNA with ambiguous n bases, and a truncated PDB. The scoring target was recognition, not completion. We wanted to know whether the agent spotted the problem or silently sent bad input downstream.
Opus recognized all three problems with or without the skill. Sonnet showed a gap on malformed DNA, improving from 3/5 recognition in baseline to 5/5 with the skill. Haiku showed gaps on both malformed DNA and the SAFE trap, improving from 3/5 to 5/5 in both cases. The truncated PDB was obvious enough that every model caught it.
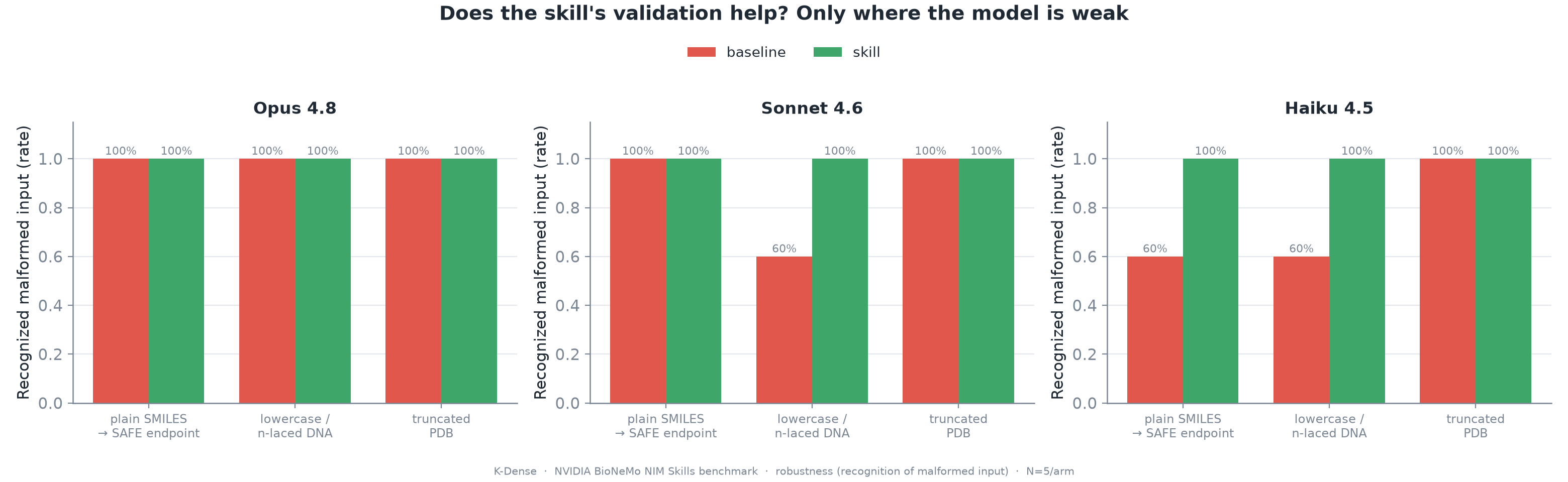 Figure 8. Robustness on malformed inputs. Curation helps only where the base model is too weak to self-correct reliably.
Figure 8. Robustness on malformed inputs. Curation helps only where the base model is too weak to self-correct reliably.
This gives a useful design rule. On a frontier model, validation guidance can be mostly insurance. On a smaller model, it becomes part of the reliability mechanism. The skill's routing guidance gets the agent to the right endpoint, while its curation guidance helps prevent cheap models from sending bad inputs confidently.
The Multi-Skill Pipeline Result
Single-call benchmarks can hide the real challenge of scientific agents. In practice, users do not want one isolated API call. They want a workflow. For this reason, we ran two multi-skill pipelines from natural-language requests.
The first pipeline chained RFdiffusion to ProteinMPNN to folding for de novo design. Both baseline and skill produced validated designs with self-consistency TM scores well above the 0.5 threshold. On a frontier model with free tool choice, the baseline could route around the hard OpenFold2 endpoint by using Boltz-2, so this pipeline showed that strong models can already complete some multi-step workflows unaided.
The second pipeline was harder and more diagnostic: target-to-hit virtual screening. The agent had to run MSA-search, fold the target, generate candidate molecules with GenMol, and dock them with DiffDock. It also had to pass artifacts across format boundaries, including A3M to structure, structure to receptor, and generated molecules into docking.
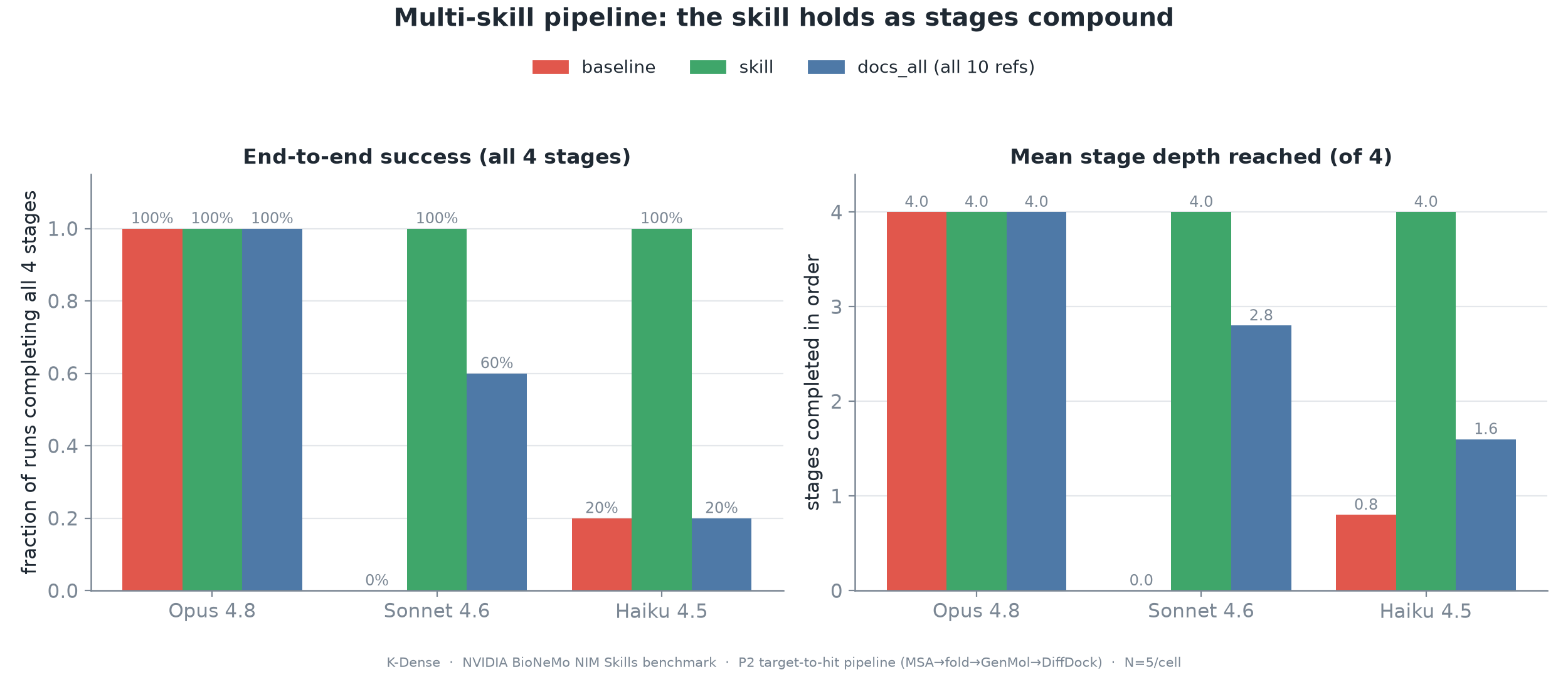 Figure 9. Four-stage target-to-hit screening pipeline. The skill completes all four stages at every model tier, while baseline and docs_all collapse on weaker models.
Figure 9. Four-stage target-to-hit screening pipeline. The skill completes all four stages at every model tier, while baseline and docs_all collapse on weaker models.
On Opus, all arms completed the full four-stage pipeline five out of five times. That is a useful result because it prevents overclaiming. A capable frontier model can navigate several routing decisions and handoffs when the task is explicit.
On weaker models, the picture changed. Sonnet baseline completed 0/5 and Haiku baseline completed 1/5. The skill completed 5/5 on both. The docs_all arm partially recovered Sonnet to 3/5 but left Haiku at 1/5. This is the case where pasting all the docs lost not only on cost, but on completion.
The economics were also striking. Haiku with the skill ran the entire screen at about $0.22 per run, roughly six times cheaper than any Opus arm, while completing every run. Sonnet with the skill completed every run at about $0.50. For workflows that need many repeated screens, that difference is not a rounding error.
There was one countervailing nuance. On Opus, docs_all was the cheapest pipeline arm because all references were already inline and the frontier model needed fewer turns. That does not overturn the progressive-disclosure result, but it clarifies it. The skill's durable advantages are resident-context scale and weak-model reliability, not guaranteed per-run cost superiority in every many-skill session on a strong model.
What This Means for Agent Skills
The most useful mental model is not "skills versus docs." It is "docs plus routing, progressive disclosure, and curation." The docs are the information. The skill is the operational package that decides when the information is relevant, keeps most of it out of context until needed, tells the agent the non-obvious route, and gives it validation checks at the point of use.
That package matters most under three conditions. It matters when the API is non-obvious, as OpenFold2 showed. It matters when there are many APIs, because dumping all references into context scales poorly. It matters when the base model is cheap or weak, because that is where routing and validation guidance convert unreliable calls into successful workflows.
The benchmark also says what skills do not do. They do not make the NVIDIA model behind the API more accurate. They do not consistently beat having the exact right docs in context if a human already selected those docs, and they do not beat all-docs on single-call success. They do not always beat all-docs in per-run cost when a frontier model needs several tools in one session. Those are real limits, and they make the positive results more credible.
Limitations
This benchmark used N=5 per case, arm, and model cell. That is enough for the large monotone effects we emphasize, but not enough to treat every small cell difference as precise. The Opus single-skill success delta, for example, includes zero because the baseline is already near ceiling.
The scoring was objective by design, based on endpoint correctness and artifact validators. We did not run a blinded LLM-judge or human audit for scientific interpretation. That means the benchmark supports claims about reaching correct, valid calls, not claims about whether the agent always draws the best biological conclusion from the result.
The docs controls used each skill's reference material, capped at 7 KB per API reference, not the entire official NVIDIA documentation corpus. A larger or differently curated documentation dump could shift the docs arms. It would not change the core scaling issue, which is that always-resident docs grow with the API surface while progressive disclosure does not.
Finally, the case set was curated and run on fixed model and API versions during the June 12-13 benchmark runs. We tested 10 skills, selected hard cases, malformed inputs, and two pipelines, but not every NIM workflow and not every possible model family. The strongest claims are therefore about mechanism: routing solves non-obvious endpoints, progressive disclosure controls context growth, and validation guidance helps weaker models avoid malformed-input failures.
Conclusion
NVIDIA NIM skills worked best where agent systems actually fail: choosing the right non-obvious call, keeping context manageable, catching bad inputs, and chaining tools without losing the thread. They did not make the underlying biomolecular models smarter, and they did not beat documentation on single-call success when all the right information was pasted into context. They did something more operational and, for production agents, more important.
The result is that a skill can turn a smaller model into a reliable caller of sophisticated scientific APIs. On hard single-call cases, Haiku with the skill beat Opus baseline at about one-fifth the cost. On a four-stage virtual-screening workflow, Haiku with the skill completed every run where Haiku baseline and Haiku with docs_all completed only one out of five. That is the practical value of the skill layer: not better science in the model, but better delivery of the science the model can already perform.
That is also why these skills belong inside K-Dense. K-Dense BYOK users can use the NVIDIA NIM skills now with their own keys, and K-Dense Web users will get the same skill layer soon, packaged into the broader scientific workflow system we have been building from the start.
Related Reading
If you want the broader context for how we think about scientific skills, start with Agent Skills: The Final Piece for AI-Powered Scientific Research, which lays out why skills close the gap between raw model capability and domain execution. For adjacent skill benchmarks, see our studies on the PyOpenMS mass spectrometry skill and the Rowan chemistry skill, which ask the same question in different scientific domains.
For infrastructure and deployment, One Skill, 78 Databases explains the routing and context design tradeoffs behind a broad scientific database skill, while GPU-Accelerate Your Science shows how K-Dense BYOK brings NVIDIA GPU acceleration into agent workflows. For the safety side of running powerful research agents, read The Sandboxed AI Scientist, our post on pairing NVIDIA OpenShell with scientific agent skills.